Acknowledgments: Your maintainer would like to thank the following for help with the FAQ: Ken Beesley, Tom Davies, Brian Goetz, Tony LaPaso, Eric Nickell, Phil Robare, David Rosenstrauch, and Michael Welle.
The latest copy of this FAQ can be found at The JavaCC FAQ.
In citing or linking to this FAQ, please use the following URI:
|
GO BACK TO BED!!"
Sheree Fitch, Sleeping Dragons All Around.
JavaCC stands for "the Java Compiler Compiler"; it is a parser generator and lexical analyzer generator. JavaCC will read a description of a language and generate code, written in Java, that will read and analyze that language. JavaCC is particularly useful when the input language has a complex structure that makes hand-crafting an input module a difficult job.
This technology originated to make programming language implementation easier -hence the term "compiler compiler"- but make no mistake that JavaCC is of use only to programming language implementors.
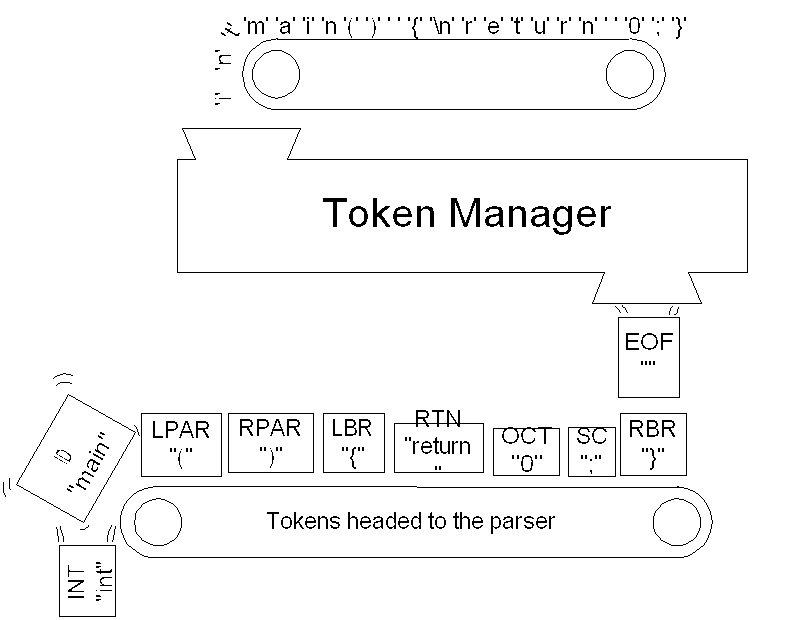
Figures 1.1 and 1.2 show the relationship between a JavaCC generated lexical analyzer (called a "token manager" in JavaCC parlance) and a JavaCC generated parser. The figures show the C as the input language. But JavaCC can handle any language -and not only programming languages- if you can describe the rules of the language to JavaCC.
The token manager reads in a sequence of characters and produces a sequence of objects called "tokens". The rules used to break the sequence of characters into a sequence of tokens obviously depend on the language; they are supplied by the programmer as a collection of "regular expressions".
The parser consumes the sequence of tokens, analyses its structure, and produces ... . Well what the parser produces is up to you; JavaCC is completely flexible in this regard1. The figure shows an "abstract syntax tree", but you might want to produce, say, a number (if you are writing a calculator), a file of assembly language (if you were writing a one-pass compiler), a modified sequence of characters (if you were writing a text processing application), and so on. The programmer supplies a collection of "Extended BNF production rules"; JavaCC uses these productions to generate the parser as a Java class. These production rules can be annotated with snippets of Java code, which is how the programmer tells the parser what to produce.
|
| Figure 1.1 The token manager converts a sequence of characters to a sequence of Token objects. |
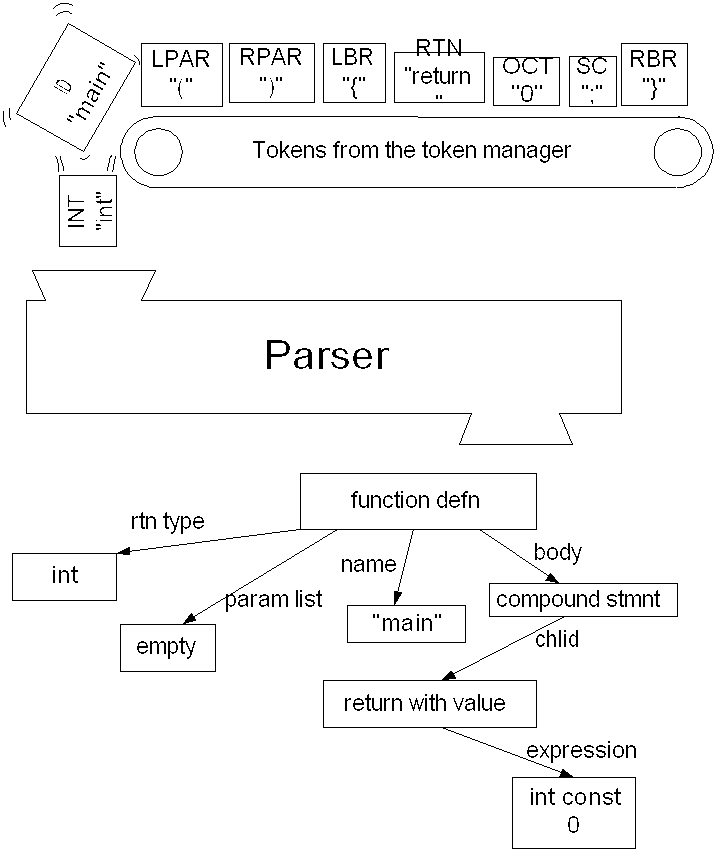 |
| Figure 1.2 The parser analyzes the sequence of tokens. |
JavaCC does not automate the building of trees (or any other specific parser output), although there are at least two tree building tools JJTree and JTB (see Chapter 6.) based on JavaCC, and building trees "by hand"with a JavaCC based parser is easy.
JavaCC does not build symbol-tables, although if you want a symbol table for a language, then a JavaCC based parser may provide a good framework.
JavaCC does not generate output languages. However once you have a tree, it is easy to generate string output from it.
JavaCC has been used to create parsers for: RTF, Visual Basic, Python, Rational Rose mdl files, XML, XML DTDs, HTML, C, C++, Java, JavaScript, Oberon, SQL, VHDL, VRML, ASN1, email headers, and lots of proprietary languages. It also get used for configuration file readers, calculators, and on and on.
comp.compilers.tools.javacc is a usenet newsgroup for discussing the JavaCC and related technologies, like JJTree and JTB.
There is also a mail-list. To subscribe send a message to javacc-interest-request@mack.eng.sun.com containing, in its body, the single word "subscribe".
Eventually the mailing list and comp.compilers.tools.javacc will be gatewayed.
Yes, but only if your question relates in some way to JavaCC, JJTree, or JTB.
The newsgroup and mailing list are not suitable fora for discussing the Java programming language or javac, which is Sun's Java compiler, or any other topic that does not relate directly to the Java Compiler Compiler.
Questions on parsing theory or parser generation in general might be better addressed to comp.compilers.
Questions directly answered in the FAQ need not be asked again in the newgroup or mailing list.
JavaCC was created by Sreeni Viswanadha and Sriram Sankar when they worked for Sun. They then formed their own company, Metamata, which is now a wholly owned subsidiary of WebGain. Through all these changes, they've kept improving JavaCC. Because of this history, JavaCC is owned by Sun Microsystems and is distributed by WebGain.
Currently (June 2002) the answer is no. However in a letter to the JavaCC mailing list on 22 March 2002, Michael Van De Vanter of Sun indicated that Sun plans to make JavaCC open source.
JavaCC is available from WebGain as a free download. The precise URL may change.
There are essentially no restrictions on the use of JavaCC. In particular you may use the Java files that JavaCC produces in any way, including incorporating them into a product that you sell. However, you are not allowed to redistribute JavaCC itself; it is free, but it is not shareware. Furthermore various .jj files that are distributed with JavaCC or that you may find on the net, may have restrictions on their use - read the copyright notices carefully.
At the moment there are no books on JavaCC.
There are some tutorial examples in the JavaCC documentation.
A couple of articles have been published in JavaWorld. See article by Chuck McManis and article by Oliver Enseling.
Your maintainer is currently writing tutorial on JavaCC, which may become a book one day.
Yes many. Most text-books on compiler technology contain more than enough background on parsing theory. Here are some suggestions
Yes. Follow this link.
The on-line documentation is currently a bit out of date. You should also read the release notes that come with the JavaCC download.
The documentation is rather terse and is much easier to read if you already know a bit about parsing theory. Nevertheless, the documentation is an indispensable resource that is in no way superceded by this FAQ.
It used to be possible to download the documentation in a big ZIP file. At the moment your maintainer does not know where the documentation can be downloaded from, but you can certainly view it on-line.
JavaCC is a program generator. Based on its input (a .jj file) version 2.1 (or later) will produce the following Java source files:
If you use the option JAVA_UNICODE_ESCAPE then SimpleCharStream.java will note be produced, but rather JavaCharStream.java. (Prior to version 2.1, one of four possible files was generated: ASCII_CharStream.java ASCII_UCodeESC_CharStream.java, UCode_CharStream.java, or UCode_UCodeESC_CharStream.java).
If you use the option USER_CHAR_STREAM, then CharStream.java (an interface) will be produced instead of the class SimpleCharStream.java. Similarly the option USER_TOKEN_MANAGER will cause the generation of an interface TokenManager.java, rather than a concrete token manager.
The boiler plate files will only be produced if they don't already exist. There are two important consequences: First, you should delete them prior to running JavaCC, if you make any changes that might require changes to these files. (See Question 2.3, "I changed option x; why am I having trouble?" .) Second, if you really want to, you can modify these files and be sure that JavaCC won't overwrite them.
Modifying any generated files should be used only as a last resort, since someday you will likely want to regenerate them and then you'll have to re-modify them. Some people have written scripts (in, say, Perl) to do the modifications for them.
The custom files are produced every time you run JavaCC.
Try deleting all files generated by JavaCC (see Question 2.2, `` What files does JavaCC produce?'' ) and then rerunning JavaCC. This issue usually comes up when the STATIC option is changed; JavaCC needs to generate new files, but it will not generate boiler-plate files unless they aren't there already.
Put a package declaration right after the PARSER_BEGIN(XXX) declaration in the .jj file.
In conventional compiling terms, a token manager is a lexical analyzer. If that is Greek to you, here is an explanation. The token manager analyzes the input stream of characters breaking it up into chunks called tokens and assigning each token a "token kind". For example suppose the input is a C file
int main() {
Then the token manager might break this into chunks as follows:
White space and comments are typically discarded, so the chunks are then
Each chunk of text is represented by an object of class Token, each with the following attributes:
and a few others.
This sequence of Token objects is produced based on regular expressions appearing in the .jj file.
The sequence is usually sent on to a parser object for further processing.
Here is one way
java.io.Reader r = new java.io.BufferedReader( sr );
XXX parser = new XXX( r );
java.io.StringReader sr = new java.io.StringReader( str );
First a definition: If a sequence x can be constructed by catenating two other sequences y and z, i.e., x=yz, then y is called a "prefix" of x.
There are three golden rules for picking which regular expression to use to identify the next token:
For example, suppose you are parsing Java, C, or C++. The following three regular expression productions might appear in the .jj file
TOKEN : { < ASSIGN : "=" > }
TOKEN : { < PLASSIGN : "+=" > }
TOKEN : { < PLUS : "+" > }
Suppose the remaining input stream starts with
Rule 1 rules out the second production. Rule 2 says that the third production is preferred over the first. The order of the productions has no effect on this example.
Sticking with Java, C, or C++, suppose you have regular expression productions
TOKEN : { < IDENT : ["a"-"z","A"-"Z", "_"]
(["a"-"z","A"-"Z","0"-"9","_"])* > }
TOKEN : { < KWINT : "int" > }
Suppose the remaining input steams starts with
then the second production would be preferred by the maximal munch rule (rule 2). But if the remaining input stream starts with
then the maximal munch rule is no help, since both rules match a prefix of length 3. In this case the KWINT production is preferred (by rule 3) because it comes first in the .jj file.
Then a TokenMgrError is thrown.
Use ~[] .
If X is the regular expression, write
|
|
Regular expression productions are classified as one of four kinds:
Lexical states allow you to bring different sets of regular expression productions in-to and out-of effect.
Suppose you wanted to write a JavaDoc processor. Most of Java is tokenized according to regular ordinary Java rules. But between a "/**" and the next "*/" a different set of rules applies in which keywords like "@param" must be recognized and where newlines are significant. To solve this problem, we could use two lexical states. One for regular Java tokenizing and one for tokenizing within JavaDoc comments. We might use the following productions:
TOKEN : {
// When @param is seen in the IN_JAVADOC_COMMENT state, it is
a token.
// Stay in the same state.
< IN_JAVADOC_COMMENT > TOKEN : {
...
// When a */ is seen in the IN_JAVADOC_COMMENT state,
switch
// back to the DEFAULT state
< IN_JAVADOC_COMMENT > TOKEN : {
// When a /** is seen in the DEFAULT state, switch to the
IN_JAVADOC_COMMENT state
Productions that are prefixed by < IN_JAVADOC_COMMENT > apply when the lexical analyzer is in the IN_JAVADOC_COMMENT state. Productions that have no such prefix apply in the DEFAULT state. It is possible to list any number of states (comma separated) before a production. The special prefix < * > indicates that the production can apply in all states.
Lexical states are also useful for avoiding complex regular expressions. Suppose you want to skip C style comments. You could write a regular expression production:
SKIP : { < "/*"(~["*"])* "*"(~["/"]
(~["*"])* "*")* "/" > }
But how confident are you that this is right?3 The following version uses a lexical state called IN_COMMENT to make things much clearer:
SKIP : {
// When any other character is seen in the IN_COMMENT state,
skip it.
< IN_COMMENT > SKIP : {
// When a */ is seen in the IN_COMMENT state, skip it and
switch back to the DEFAULT state
< IN_COMMENT > SKIP : {
// When a /* is seen in the DEFAULT state, skip it and switch
to the IN_COMMENT state
The previous example also illustrates a subtle behavioural difference between using lexical states and performing the same task with a single, apparently equivalent, regular expression. Consider tokenizing the C "statement":
i = j/*p ;
Assuming that there are no occurrences of */ later in the file, this is an error (since a comment starts, but doesn't end) and should be diagnosed. If we use a single, complex, regular expression to find comments, then the lexical error will be missed and, in this example at least, a syntactically correct sequence of seven tokens will be found. If we use the lexical states approach then the behaviour is different, though again incorrect; the comment will be skipped; an EOF token will be produced after the token for "j"4; no error will be reported. We can correct the lexical states approach, however, with the use of MORE; see Question 3.11, "What is MORE?" .
Yes, but it is very easy to create bugs by doing so. You can call the token manager's method SwitchTo from within a semantic action in the parser like this
{ token_source.SwitchTo(name_of_state) ; }
However, owing to look-ahead, the token manager may be well ahead of the parser. Consider Figure 1.2; at any point in the parse, there are a number of tokens on the conveyer belt, waiting to be used by the parser; technically the conveyer belt is a queue of tokens held within the parser object. Any change of state will take effect for the first token not yet in the queue. Syntactic look-ahead usually means there is at least one token in the queue, but there may be many more.
If you are going to force a state change from the parser be sure that, at that point in the parsing, the token manager is a known and fixed number of tokens ahead of the parser, and that you know what that number is.
If you ever feel tempted to call SwitchTo from the parser, stop and try to think of an alternative method that is harder to get wrong.
Brian Goetz submitted the following code to make sure that, when a SwitchTo is done, any queued tokens are removed from the queue. There are three parts to the solution:
}
TOKEN_MGR_DECLS : {
Regular expression productions are classified as one of four kinds:
MORE means that no token should be produced yet. Rather the characters matched will form part of the next token to be recognized. MORE means that there will be more to the token. After a sequence of one or more MORE productions have been applied, we must reach a production that is marked TOKEN, SKIP, SPECIAL_TOKEN. The token produced (or not produced in the case of SKIP) will contain the saved up characters from the preceding MORE productions. Note that if the end of the input is encountered when the token manager is looking for more of a token, then a TokenMgrError is thrown. The assumption made by JavaCC is that the EOF token should correspond exactly to the end of the input, not to some characters leading up to the end of the input.
Let's revisit and fix the comment example from Question 3.8, "What are lexical states all about?" . The problem was that unterminated comments were simply skipped rather than producing an error. We can correct this problem using MORE productions to combine the entire comment into a single token.
MORE : {
// When any other character is seen in the IN_COMMENT state,
skip it.
< IN_COMMENT > MORE : {
// When a */ is seen in the IN_COMMENT state, skip it and
switch back to the DEFAULT state
< IN_COMMENT > SKIP : {
// When a /* is seen in the DEFAULT state, skip it and switch
to the IN_COMMENT state
Suppose that a file ends with "/*a". Then no token can be recognized, because the end of file is found when the token manager only has a partly recognized token. Instead a TokenMgrError will be thrown.
The file is likely missing a newline character (or the equivalent) at the end of the last line.
These parsers use lexical states and MORE type regular expression productions to process single line comments thusly:
< IN_SINGLE_LINE_COMMENT > SPECIAL_TOKEN : {
< IN_SINGLE_LINE_COMMENT > MORE : {
MORE : {
Clearly if an EOF is encountered while the token manager is still looking for more of the current token, there should be a TokenMgrError thrown.
Both the Java and the C++ standards agree with the example .jj files, but some compilers are more liberal and do not insist on that final newline. If you want the more liberal interpretation, try
SPECIAL_TOKEN : {
Sometimes you want some piece of Java code to be executed immediately after a token is matched. Lexical actions are placed immediately after the regular expression in a regular expression production. For example:
}
TOKEN : {
The Java statement { tabcount+=1; } will be executed after the production is applied.
A common token action is simply a subroutine that is called after each Token is matched. Note that this does not apply to "skipped tokens" nor to "special tokens".
If you don't want any TokenMgrErrors being thrown, try putting a regular expression production at the very end of your .jj file that will match any character:
{
< UNEXPECTED_CHAR : ~[] >
}
< * > TOKEN :
However, this may not do the trick. In particular, if you use MORE, it may be hard to avoid TokenMgrErrors altogether. It is best to make a policy of catching TokenMgrErrors as well as ParseExceptions, whenever you call an entry point to the parser.
In version 2.1 a new feature was introduced. You now have the option that the line and column numbers will not be recorded in the Token objects. The option is called KEEP_LINE_COLUMN. The default is true, so not knowing about this option shouldn't hurt you.
However, there appears to be a bug in the GUI interface to JavaCC (javaccw.exe), which sets this option to false (even if you explicitly set it to true in the .jj file).
The solution is to delete all generated files (see Question 2.3, `` I changed option x; why am I having trouble?'' ) and henceforth to not use the GUI interface to JavaCC.
This question is dependant on the application. A lot of simple applications only require a token manager. However, many people try to do too much with the lexical analyzer, for example they try to write an expression parser using only the lexical analyzer.
JavaCC's generated parser classes work by the method of "recursive descent". This means that each BNF production in the .jj file is translated into a subroutine with roughly the following mandate:
If there is a prefix of the input sequence of tokens that matches this nonterminal's definition,then remove that prefix from the input sequence
else throw a ParseException
Left-recursion is when a nonterminal contains a recursive reference to itself that is not preceded by something that will consume tokens.
The parser class produced by JavaCC works by recursive descent. Left-recursion is banned to prevent the generated subroutines from calling themselves recursively ad-infinitum. Consider the following obviously left recursive production
|
}
void A() : {} {
This will translate to a Java subroutine of the form
}
void A() : {} {
Now if the condition is ever true, we have an infinite recursion.
Luckly JavaCC will produce an error message, if you have left-recursive productions.
To use JavaCC effectively you have to understand how it looks ahead in the token stream to decide what to do. Your maintainer strongly recommends reading the lookahead mini-tutorial in the JavaCC documentation. (See Section2.1) . The following questions of the FAQ address some common problems and misconceptions about lookahead. Ken Beesley has kindly contributed some supplementary documentation.
Some of JavaCC's most common error messages goes something like this
Warning: Choice conflict ...Consider using a lookahead of 2 for ...
Read the message carefully. Understand why there is a choice conflict (choice conflicts will be explained shortly) and take appropriate action. The appropriate action, in my experience, is rarely to use a lookahead of 2.
So what is a choice conflict. Well suppose you have a BNF production
|
}
void a() : {} {
When the parser applies this production, it must choose between expanding it to < ID > b() and expanding it to < ID > c(). The default method of making such choices is to look at the next token. But if the next token is of kind ID then either choice is appropriate. So you have a "choice conflict". For alternation (i.e. |) the default choice is the first choice.
To resolve this choice conflict you can add a "LOOKAHEAD specification"to the first alternative. For example, if nonterminal b and nonterminal c can be distinguished on the basis of the token after the ID token, then the parser need only lookahead 2 tokens. You tell JavaCC this by writing:
|
}
void a() : {} {
Ok, but suppose that b and c can start out the same and are only distinguishable by how they end. No predetermined limit on the length of the lookahead will do. In this case, you can use "syntactic lookahead". This means you have the parser look ahead to see if a particular syntactic pattern is matched before committing to a choice. Syntactic lookahead in this case would look like this:
|
}
void a() : {} {
Another way to resolve conflicts is to rewrite the grammar. The above nonterminal can be rewritten as
}
void a() : {} {
which may resolve the conflict.
Choice conflicts also come up in loops. Consider
}
void paramList() : {} {
There is a choice of whether to stay in the * loop or to exit it and process the optional ELLIPSIS. But the default method of making the choice based on the next token does not work; a COMMA token could be the first thing seen in the loop body, or it could be the first thing after the loop body. For loops the default choice is to stay in the loop.
To solve this example we could use a lookahead of 2 at the appropriate choice point (assuming a param can not be empty and that one can't start with an ELLIPSIS.
}
void paramList() : {} {
We could also rewrite the grammar, replacing the loop with a recursion.
Sometimes the right think to do is nothing. Consider this classical example, again from programming languages
{
|
}
void statement() : {}
Because an ELSE token could legitimately follow a statement, there is a conflict. The fact that an ELSE appears next is not enough to indicate that the optional " < ELSE > statement()"should be parsed. Thus there is a conflict. The default for parsers is to take an option rather than to leave it; and that turns out to be the right interpretation in this case (at least for C, C++, Java, Pascal, etc.). If you want, you can write:
{
|
}
void statement() : {}
to suppress the warning.
No. JavaCC will not report choice conflict warnings if you use a LOOKAHEAD specification. The absence of a warning doesn't mean that you've solved the problem correctly, it just means that you added a LOOKAHEAD specification.
Consider the following example:
{
|
void eg() : {}
}
Clearly the lookahead is insufficient (lookahead 3 would do the trick), but JavaCC produces no warning. When you add a LOOKAHEAD specification, JavaCC assumes you know what you are doing and suppresses any warnings.
No.
No!
This can is a bit surprising. Consider a grammar
|
void a( ) : { } {
}
void w() : {} { ''w'' }
void x() : {} { ''x'' }
void y() : {} { ''y'' }
void start( ) : { } {
}
and an input sequence of "wxy". You might expect that this string will be parsed without error, but it isn't. The lookahead on a() fails so the parser takes the second (wrong) alternative in start. So why does the lookahead on a() fail? The lookahead specification within a() is intended to steer the parser to the second alternative when the remaining input starts does not start with "wy". However during syntactic lookahead, this inner syntactic lookahead is ignored. The parser considers first whether the remaining input, "wxy", is matched by the alternation (w() | w() x()). First it tries the first alternative w(); this succeeds and so the alternation (w() | w() x()) succeeds. Next the parser does a lookahead for y() on a remaining input of "xy"; this of course fails, so the whole lookahead on a() fails. Lookahead does not backtrack and try the second alternative of the alternation. Once one alternative of an alternation has succeeded, the whole alternation is considered to have succeeded; other alternatives are not considered. Nor does lookahead pay attention to nested synactic LOOKAHEAD specifications.
This problem usually comes about when the LOOKAHEAD specification looks past the end of the choice it applies to. So a solution to the above example is to interchange the order of choices like this:
}
void a( ) : { } {
Another solution sometimes is to distribute so that the earlier choice is longer. In the above example, we can write
}
void a( ) : { } {
Generally it is a bad idea to write syntactic look-ahead specifications that
look beyond the end of the choice they apply to. If you have a production
|
void a() : {} { LOOKAHEAD(C) A | B }
then it is a good idea that L(C) (the language of strings
matched by C) is a set of prefixes of L(A). That is
|
No.
No.
Yes. It is also evaluated during evaluation of LOOKAHEAD( n ), for n > 1.
Yes to a point.
The problem is that semantic lookahead specifications are evaluated during syntactic lookahead (and during lookahead of more than 1 token). But the subroutine generated to do the syntactic lookahead for a nonterminal will not declare the parameters or the other local variables of the nonterminal. This means that the code to do the semantic lookahead will fail to compile (in this subroutine) if it mentions parameters or other local variables.
So if you use local variables in a semantic lookahead specification within the BNF production for a nonterminal n, make sure that n is not used in syntactic lookahead, or in a lookahead of more than 1 token.
This is a case of three rights not making a right! It is right that semantic lookahead is evaluated in during syntactic lookahead, it is right (or at least useful) that local variables can be mentioned in semantic lookahead, and it is right that local variables do not exist during syntactic lookahead. Yet putting these three features together tricks JavaCC into producing uncompilable code. Perhaps a future version of JavaCC will put these interacting features on a firmer footing.
Well first off JavaCC is more flexible. It lets you use multiple token lookahead, syntactic lookahead, and semantic lookahead. If you don't use these features, you'll find that JavaCC is only subtly different from LL(1) parsing; it does not calculate "follow sets"in the standard way - in fact it can't as JavaCC has no idea what your starting nonterminal will be.
It is usually a bad idea to try to have the parser try to influence the way the token manager does its job. The reason is that the token manager may produce tokens long before the parser consumes them. This is a result of lookahead.
Often the work-around is to use lexical states to have the token manager change its behaviour on its own.
In other cases, the work-around is to have the token manager not change its bevhaviour and have the parser compensate. For example in parsing C, you need to know if an identifier is a type or not. If you were using lex or yacc, you would probably write your parser in terms of token kinds ID and TYPEDEF_NAME. The parser will add typedef names to the symbol table after parsing each typedef definition. The lexical analyzer will look up identifiers in the symbol table to decide which token kind to use. This works because with lex and yacc, the lexical analyzer is always one token ahead of the parser. In JavaCC, it is better to just use one token kind, ID, and use a nonterminal in place of TYPEDEF_NAME:
void typedef_name() : {} {
But you have to be careful using semantic look-ahead like this. It could still cause trouble. Consider doing a syntactic lookahead on nonterminal `statement'. If the next statement is something like
{ typedef int T ; T i ; i = 0 ; return i ; }
The lookahead will fail since the semantic action putting T in the symbol table will not be done during the lookahead! Luckly in C, there should be no need to do a syntactic lookahead on statements.
[TBD. Think through this example very carefully.]
As with communication between from the parser to the token manager, this can be tricky because the token manager is often well ahead of the parser.
For example, if you calculate the value associated with a particular token kind in the token manager and store that value in a simple variable, that variable may well be overwritten by the time the parser consumes the relevant token. Instead you can use a queue. The token manager puts information into the queue and the parser takes it out.
Another solution is to use a table. For example in dealing with #line directives in C or C++, you can have the token manager fill a table indicating on which physical lines the #line directives occur and what the value given by the #line is. Then the parser can use this table to calculate the "source line number"from the physical line numbers stored in the Tokens.
It is possible to embed a regular expression within a BNF production. For example
TOKEN : { < ABC : "abc" > }
//A BNF production
void nonterm() : {} {
//A regular expression production
}
There are six regular expressions within the BNF production. The first is simply a Java string and is the same string that appears in the earlier regular expression production. The second is simply a Java string, but does not (we will assume) appear in a regular expression production. The third is a "complex regular"expression. The next three simply duplicate the first three.
The code above is essentially equivalent to the following:
TOKEN : { < ABC : "abc" > }
TOKEN : { < ANON0 : "def" > }
TOKEN : { < ANON1 : < (["0"-"9"])+ > }
TOKEN : { < ANON2 : < (["0"-"9"])+ > }
//A BNF production
void nonterm() : {}
{
< ABC >
//A regular expression production
}
In general when a regular expression is a Java string and identical to regular expression occurring in a regular expression production5, then the Java string is interchangeable with the token kind from the regular expression production.
When a regular expression is a Java string, but there is no corresponding regular expression production, then JavaCC essentially makes up a corresponding regular expression production. This is shown by the "def"which becomes an anonymous regular expression production. Note that all occurrences of the same string end up represented by a single regular expression production.
Finally consider the two occurrences of the complex regular expression < (["0"-"9"])+ > . Each one is turned into a different regular expression production. This spells trouble, as the ANON2 regular expression production will never succeed. (See Question 3.3. `` What if more than one regular expression matches a prefix of the remaining input?'' )
See also Question 4.17, `` When should regular expressions be put directly into a BNF production?'' .
First read Question 4.16, `` What does it mean to put a regular expression within a BNF production?'' .
For regular expressions that are simply strings, you might as well put them directly into the BNF productions, and not bother with defining them in a regular expression production.6 For more complex regular expressions, it is best to give them a name, using a regular expression production. There are two reasons for this. The first is error reporting. If you give a complex regular expression a name, that name will be used in the message attached to any ParseExceptions generated. If you don't give it a name, JavaCC will make up a name like " < token of kind 42 > ". The second is perspicuity. Consider the following example:
{
}
void letter_number_letters() : {
The intention is to be able to parse strings like "a9abc". Written this way it is a bit hard to see what is wrong. Rewrite it as
TOKEN : < NUMBER : ["0"-"9"] > }
TOKEN : < LETTERS : (["a"-"z"])+
> }
void letter_number_letters() : {
{
}
TOKEN : < LETTER : ["a"-"z"] >
}
and it might be easier to see the error. On a string like "z7d"the token manager will find a LETTER, a NUMBER and then another LETTER; the BNF production can not succeed. (See Question 3.3, `` What if more than one regular expression matches a prefix of the remaining input?'' )
This turns out to be a bit tricky. Of course you can list all the alteratives. Say you want A, B, C, each optionally, in any order, with no duplications; well there are only 16 possibilities:
|
|
|
|
|
}
void abc() : {} {
This approach is already ugly and won't scale.
A better approach is to use semantic actions to record what has been seen
}
void abc() : {} {
The problem with this approach is that it will not work well with syntactic lookahead. Ninety-nine percent of the time you won't care about this problem, but consider the following highly contrived example:
{
|
void toughChoice() : {}
}
When the input is two A's followed by two B's, the second choice should be taken. If you use the first (ugly) version of abc, above, then that's what happens. If you use the second (nice) version of abc, then the first choice is taken, since syntactically abc is ( < A > | < B > | < C > )*.
In Java, C++, and many other languages, keywords, like "int", "for", "throw"and so on are reserved, meaning that you can't use them for any purpose other than that defined by the language; in particular you can use them for variable names, function names, class names, etc. In some applications, keywords are not reserved. For example, in the PL/I language, the following is a valid statement
if if = then then then = else ; else else = if ;
For a more modern example, in parsing URL's, we might want to treat the word "http"as a keyword, but we don't want to prevent it being used as a host name or a path segment. Suppose we write the following productions7:
TOKEN : { < LABEL : < ALPHANUM > | < ALPHANUM > ( < ALPHANUM > |"-")* < ALPHANUM > }
void httpURL() : {} { < HTTP > ":""//"host()
port_path_and_query() }
void host() : {} { < LABEL > ("." < LABEL >
)* }
TOKEN : { < HTTP : "http" > }
Both the regular expressions labelled HTTP and LABEL, match the string "http". As covered in Question 3.3, `` What if more than one regular expression matches a prefix of the remaining input?'' the first rule will be chosen; thus the URL
will not be accepted by the grammar. So what can you do? There are basically two strategies: replace keywords with semantic lookahead, or put more choices in the grammar.
Replacing keywords with semantic lookahead. Here we eliminate the offending keyword production. In the example we would eliminate the regular expression production labelled HTTP. Then we have to rewrite httpURL as
void httpURL() : {} {
The added semantic lookahead ensures that the URL really begins with a LABEL which is actually the keyword "http". [TBD Check this example.]
Putting more choices in the grammar. Going back to the original grammar, we can see that, the problem is that where we say we expect a LABEL we actually intended to expect either a LABEL or a HTTP. We can rewrite the last production as
void label() : {} { < LABEL > | < HTTP > }
void host() : {} { label() ("."label())* }
Perhaps you forgot the < EOF > in the production for your start nonterminal.
You need to add semantic actions. Semantic actions are bits of Java code that get executed as the parser parses.
Each Token object has a pointer to the next Token object. Well that's not quite right. There are two kinds of Token objects. There are regular token objects, created by regular expression productions prefixed by the keyword TOKEN. And, there are special token objects, created by regular expression productions prefixed by the keyword SPECIAL_TOKEN. Each regular Token object has a pointer to the next regular Token object. We'll deal with the special tokens later.
Now since the tokens are nicely linked into a list, we can represent a sequence of tokens occurring in the document with a class by pointing to the first token in the sequence and the first token to follow the sequence.
}
class TokenList {
We can create such a list using semantic actions in the parser like this:
} {
}
TokenList CompilationUnit() : {
To print regular tokens in the list, we can simply traverse the list
}
class TokenList {
This method of traversing the list of tokens is appropriate for many applications.
Here is some of what I got from printing the tokens of a Java file:
|
}
class TokenList {
If you want to capture and print a whole file, don't forget about the special tokens that precede the EOF token.
TBD. Your maintainer knows little about either of these tools and would especially appreciate volunteers to contribute to this part of the FAQ.
These are preprocessors that produce .jj files. The .jj files produced will produce parsers that produce trees.
JJTree comes with JavaCC. See Question 1.9, `` Where can I get JavaCC?''. .
See JTB: The Java Tree Builder Homepage..
First look in Dongwon Lee's JavaCC Grammar Repository.
Then ask the newsgroup or the mailing list.
See the examples that come with JavaCC.
See any text on compiling.
See Parsing Epressions by Recursive Descent.
A lot of people who want to write an interpreter for a programming language seem to start with a calculator for expressions, evaluating during parsing, as is quite reasonable. Then they add, say, assignments and if-then-else statements, and all goes well. Now they want to add loops. Having committed to the idea that they are evaluating while parsing they want to know how back up the token manager so that loop-bodies can be reparsed, and thus reevaluated, over and over and over again.
It's an interesting idea, but it's clear that JavaCC will not make this approach pleasant. Your maintainer suggests translating to an intermediate code during parsing, and then executing the intermediate code. A tree makes a convenient intermediate code. Consider using JJTree or JTB (see Chapter 6 ).
If you still want to back up the token manager. I suggest that you start by tokenizing the entire file, capturing the tokens in a list (see Question 5.2, `` How do I capture and traverse a sequence of tokens?''. ) or, better, a Vector. Now write a custom token manager that delivers this captured sequence of tokens, and also allows backing up.
[TBD. Your maintainer would welcome comparisons with ANTLR, CUP, JLex, JFlex, and any others that users can contribute. My limited understanding is that CUP is similar to Yacc and Bison, and that JLex and JFlex are similar to Lex and Flex.]
It's true that there are strictly more languages that can be described by LALR(1) grammars than by LL(1) grammars. Furthermore almost every parsing problem that arises in programming languages has an LALR(1) solution and the same can not be said for LL(1).
But the situation in parser generators is a big more complicated. JavaCC is based on LL(1) parsing, but it allows you to use grammars that are not LL(1). As long as you can use JavaCC's look-ahead specification to guide the parsing where the LL(1) rules are not sufficient, JavaCC can handle any grammar that is not left-recursive. Similarly tools based on LALR(1) or LR(1) parsing generally allow input grammars outside those classes.
A case in point is the handling of if-statements in C, Java, and similar
languages. Abstracted, the grammar is
|
Lex is the lexical analyzer supplied for many years with most versions of Unix. Flex is a freely distributable relative associated with the GNU project. JavaCC and lex/flex are actually quite similar. Both work essentially the same way, turning a set of regular expressions into a big finite state automaton and use the same rules (for example the maximal munch rule). The big difference is the lex and flex produce C, whereas JavaCC produces Java.
One facility that lex and flex have, that JavaCC lacks, is the ability to look ahead in the input stream past the end of the matched token. For a classic example, to recognize the Fortran keyword "DO", you have to look forward in the input stream to find a comma. This is because
DO 10 I = 1,20
is a do-statement, whereas
DO 10 I
is an assignment to a variable called DO10I (Fortran totally ignores blanks). Dealing with this sort of thing is easy in lex, but very hard in JavaCC.
However JavaCC does have some nice features that Lex and Flex lack: Common token actions, MORE rules, SPECIAL_TOKEN rules.
Yacc is a parser generator developed at Bell labs. Bison is a freely distributable reimplementation associated with the GNU project. Yacc and Bison produce C whereas JavaCC produces Java.
The other big difference is that Yacc and Bison work bottom-up, whereas JavaCC works top-down. This means that Yacc and Bison make choices after consuming all the tokens associated with the choice, whereas JavaCC has to make its choices prior to consuming any of the tokens associated with the choice. However, JavaCC's lookahead capabilities allow it to peek well ahead in the token stream without consuming any tokens; the lookahead capabilities ameliorate most of the disadvantages of the top-down approach.
Yacc and Bison require BNF grammars, whereas JavaCC accepts EBNF grammars. In a BNF grammar, each nonterminal is described as choice of zero or more sequences of zero or more terminals and nonterminals. EBNF extends BNF with looping, optional parts, and allows choices anywhere, not just at the top level. For this reason Yacc/Bison grammars tend to have more nonterminals than JavaCC grammars and to be harder to read. For example the JavaCC production
void eg() : {} {a() (b() [","])* }
might be written as
;
eg1 : /* empty */
;
optcomma : /* empty */
;
eg : a eg1
More importantly, it is often easier to write semantic actions for JavaCC grammars than for Yacc grammars, because there is less need to communicate values from one rule to another.
Yacc has no equivalent of JavaCC's parameterized nonterminals. While it is fairly easy to pass information up the parse-tree in Yacc (and JavaCC), it is hard to pass information down the tree in Yacc. For example, if in the above example, if we computed information in parsing the a that we wanted to pass to the b, this is easy in JavaCC, using parameters, but hard in Yacc.
As the example above shows, Yacc has no scruples about left-recursive productions.
My assessment is that if your language is totally unsuitable for top-down parsing, you'll be happier with a bottom-up parser like Yacc or Bison. However, if your language can be parsed top-down without too many appeals to lookahead, then JavaCC's combination of EBNF and parameters can make life much more enjoyable.
1Another way of looking at it is that JavaCC is of little help in this regard. However, if you want to produce trees there are two tools, based on JavaCC, that are less flexible and more helpful, these are JJTree and JTB. See Chapter 6 .
2JavaCC's terminology here is a bit unusual. The conventional name for what JavaCC calls a "token kind" is "terminal" and the set of all token kinds is the älphabet" of the EBNF grammar.
3This
example is quoted from
|
< "/*"(~["*"] |("*")+ ~["/"])* ("*")+ "/"
>
... I think.
4The rule that an EOF token is produced at the end of the file applies regardless of the lexical state.
5And provided that regular expression applies in the DEFAULT lexical state.
6Ok there are still a few reasons to use a regular expression production. One is if you are using lexical states other than DEFAULT. Another is if you want to ignore the case of a word. Also, some people just like to have an alphabetical list of their keywords somewhere.
7This
example is based on the syntax for HTTP URLs in RFC: 2616 of the IETF by
R. Fielding, et. al. However, I've made a number of
simplifications and omissions for the sake of a simpler example.